

Munger Nunca Pisó un Gimnasio
Tomó Coca-Cola y comió dulces hasta los 99. La dieta que de verdad importaba nunca tuvo que ver con la comida.


I. La Dieta de Charlie Munger
Charlie Munger desayunaba peanut brittle de See’s Candies. La marca de dulces que él mismo le ayudó a comprar a Berkshire en 1972. Warren Buffett, su socio durante seis décadas, toma cinco Coca-Colas al día — empieza una en el desayuno con papas fritas de McDonald’s — y dice, sin pestañear, que un cuarto de su cuerpo es Coca-Cola. Ninguno de los dos pisó un gimnasio en su vida adulta. Ninguno de los dos contrató a un nutricionista, ni hizo ayuno intermitente, ni se midió el VO2 max, ni se inyectó un péptido.
Munger murió el 28 de noviembre de 2023. Le faltaban treinta y cuatro días para cumplir cien años. Estuvo lúcido hasta el último mes — dando entrevistas de tres horas, citando de memoria libros que había leído cuatro décadas atrás, corrigiendo cifras. Buffett tiene noventa y cinco y sigue leyendo 10-Ks. Dos hombres que violaron sistemáticamente cada regla de la industria de la longevidad, y que sin embargo terminaron — uno casi, el otro probablemente — con un siglo de vida útil y la cabeza intacta.
La industria del bienestar lo llamaría “coincidencia”. Dos genios, suerte genética, supervivencia estadística. Yo no creo en esa coincidencia. Creo que estábamos midiendo el órgano equivocado.
Munger lo dijo él mismo, con la franqueza brutal que lo caracterizaba: pasó toda su vida adulta leyendo. No leyendo earnings calls — leyendo física, biología, historia, psicología, ingeniería. Decía que nunca conoció a una persona sabia que no leyera todo el tiempo. Buffett estima que dedica el ochenta por ciento de su jornada a leer y pensar. Esa es la rutina. Esa es la dieta. No la Coca-Cola — la Coca-Cola es el ruido. La señal es que esos dos cerebros nunca dejaron de actualizar sus pesos.
Hace unas semanas leí algo de Peter Diamandis que me gusto mucho. La tesis es incómoda y es, creo, una de las cosas más importantes que un inversionista — o cualquier persona que piense vivir treinta o cincuenta años más — debería entender. Y se conecta directamente con lo que repito hace años: tu portafolio vale exactamente lo que vale tu dieta de información.
II. Tu Cerebro es el Modelo Fundacional Original
Llevamos tres años hablando de modelos de lenguaje como si fueran la cosa más extraordinaria que ha producido la ingeniería. Y lo son. Pero hay un foundation model que es anterior, más grande, y mejor — y lo tienes adentro del cráneo.
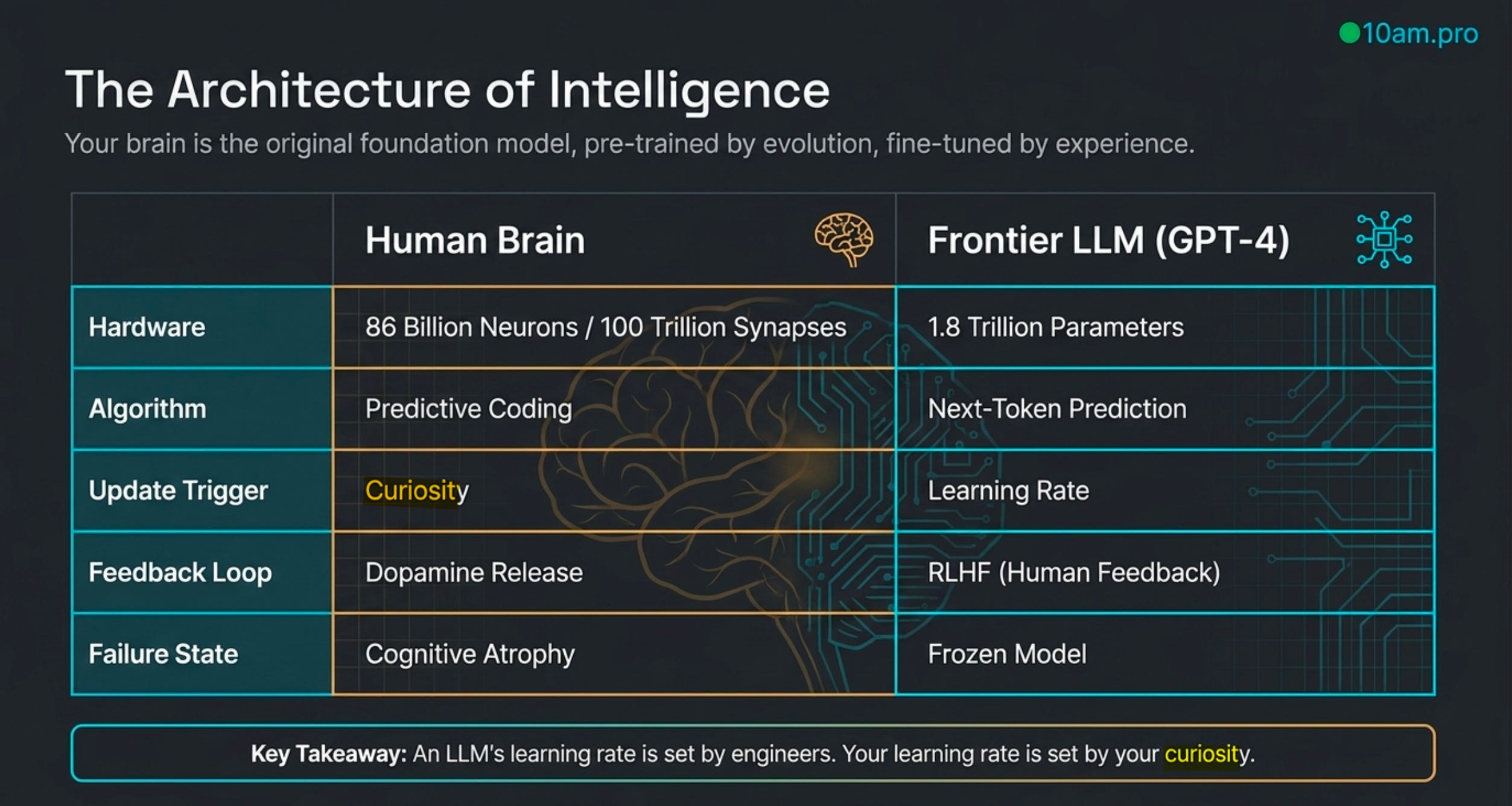
GPT-4 corre sobre aproximadamente 1.8 trillones de parámetros. Tu cerebro tiene 86 mil millones de neuronas conectadas por cien trillones de sinapsis. El LLM se pre-entrenó con todo el texto de internet; tu cerebro se pre-entrenó con cuatro mil millones de años de evolución y se fine-tunea, cada día, con tu experiencia. La arquitectura es asombrosamente paralela. El modelo de Silicon Valley predice el siguiente token. El tuyo hace predictive coding — está constantemente prediciendo lo que viene y corrigiéndose cuando se equivoca.
Pero hay una diferencia que importa más que todas las demás, y es la que define este escrito.
En un LLM, el learning rate — la velocidad a la que el modelo ajusta sus pesos cuando recibe información nueva — lo fija un ingeniero. Es un hiperparámetro. Alguien en un laboratorio decide ese número antes de entrenar. En tu cerebro, el learning rate no lo fija ningún ingeniero. Lo fija tu curiosidad.
Eso no es una metáfora bonita. Es mecánica neuroquímica, y la voy a explicar en un momento. Pero la implicación es la siguiente: el modelo de OpenAI, una vez entrenado, queda congelado hasta que los ingenieros decidan correr otra pasada. Tu modelo no tiene por qué congelarse nunca. Puede seguir entrenándose hasta el último día. La pregunta — la única pregunta — es si tú dejas que se entrene, o si lo apagas.
La mayoría de la gente lo apaga. Y lo apaga temprano. Mucho más temprano de lo que cualquiera imaginaría.
III. The System Crash
A los cinco años, antes de entrar a primaria, un niño promedio hace ciento siete preguntas por hora. Ciento siete. Es ingestión de datos a full throttle — el modelo en plena fase de pre-entrenamiento, absorbiendo el mundo sin filtro.

A los seis, después de un año de primer grado, ese número cae a 2.3 preguntas por hora. A los once, en quinto grado, llega a 0.48. Menos de una pregunta por hora.
